1. Motivation
现有的基于颜色图像指导的深度图像超分辨率重建方法,都需要一个额外的分支来从高分辨率彩色图像中提取需要的结构指导信息。但这种模式在实际应用中会受到很多限制。
首先,在实际应用中,与深度图像视角相同且高度配准的高分辨率彩色图像难以直接获取,需要进一步的标定、配准和校正,从而导致了现有训练好的模型无法使用。其次,对于高分辨率彩色图像的处理,极大增加了内存消耗和计算负担,这阻碍了深度图像超分辨率在实际应用中的实时性。此外,高分辨率彩色特征的准确结构信息可以辅助深度图像超分辨率的细节重建,然而,彩色图像的纹理不连续与深度图像的简单结构存在不一致性,彩色图像中同时又包含大量纹理信息,这会导致明显的伪影,如纹理复制和深度泄漏。因此,如何利用有效地利用彩色信息帮助恢复深度图,同时又满足实际测试环境中的实时性要求,还有待进一步探索。
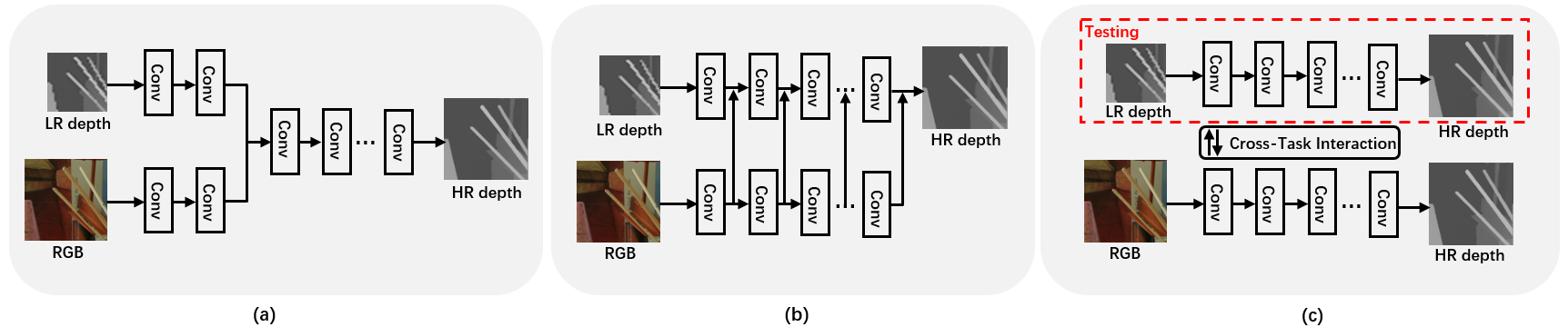
本文希望缓解现有基于彩色指导的深度超分辨率方法的局限性现有的颜色引导的 DSR 方法通过两路融合的架构来利用 RGB-D 图像对,这种架构需要一个额外的分支从 RGB 图像提取结构指导。, 如经典的彩色图像与深度图像联合滤波框架如图 1(a)所示,彩色图像和低分辨率深度图像通常由单独的支路处理并通过联合分支“过滤”以输出高分辨率的结果 。但是,由于网络中特定层的特征聚合方式较为简单,来自彩色图像的高频结构信息在特征提取过程中更容易丢失。 和彩色特征多尺度指导框架如图 1(b)所示,一些新颖的方法采用了新的特征聚合范式,即多尺度融合,以允许网络在不同的层级学习丰富的层次特征。这使得网络可以保留更多的空间细节,以便恢复精细结构和大尺度的结构。,从而提出了基于跨任务场景结构知识迁移的单张场景深度图像超分辨率方法,如图 1(c)所示,为缓解上述问题提供了一个全新的解决思路。
2. Contribution
本文的主要贡献可总结如下:
- (1) 本文提出的 DSR 范式是第一个在训练阶段以多种模态作为输入进行学习,但仅在单个 LR 深度模态上进行测试的工作。本文提出的基于跨任务场景结构知识迁移的单张深度图像超分辨率框架,在训练阶阶段构建了一个以彩色图像为输入的深度估计任务,以及以低分辨率深度图像为输入的深度超分辨率任务,并对两个任务进行协同训练;
- (2) 提出了一个跨任务知识交互模块从彩色图像中蒸馏需要的结构信息辅助深度图像的恢复,以鼓励 DSRNet 和 DENet 在协作训练模式下相互学习;
- (3) 提出了多空间知识蒸馏策略以及不确定度引导的结构正则化约束来实现双边知识迁移,提升深度超分辨率模型的性能。
3. Method
3.1 基于跨任务场景结构知识迁移的单张深度图像超分辨率网络
图 2 展示了基于跨任务场景结构知识迁移的单张深度图像超分辨率的框架,主要由深度超分辨率网络(DSRNet)、深度估计网络(DENet)和中间跨任务交互模块(CT)三部分组成。给定一组配对的 LR-HR 深度图像 $\left\{D_{l r}^{(k)}, D_{h r}^{(k)}\right\}_{k=1}^{M}$ 以及对应的 HR 彩色图像 $\{I(k)\}_{k=1}^{M}$ 作为训练数据,其中 $M$ 为训练数据的个数,最终的目标是训练 DSRNet 使其能够从单张 LR 深度图像 $\left\{D_{l r}^{(k)}\right\}_{k=1}^{M}$ 得到超分结果 $\left\{D_{s r}^{(k)}\right\}_{k=1}^{M}$。

DSRNet 的结构是基于 deep back-projection network (DBPN) 的网络单元设计的,如图 2 红框所示,该网络通过将 HR 表示迭代投影到 LR 空间域,再映射回 HR 域,有效地增强了特征表示。首先通过三个简单的卷积层对 $D_{lr}$ 提取特征得到 $D_{sr}^{shallow}$,然后将 $D_{sr}^{shallow}$ 送入主干网络获得 HR 特征 $\{F_{sr}^n\}_{n=1}^N$,$N$ 是堆叠的 DBPN 模块的数量。最后将 $F_{sr}^N$ 通过一个简单的卷积块映射到输出空间。得到超分辨率网络的输出 $D_{sr}$。
DENet 的结构与 DSRNet 类似,但是用了更深的残差块代替 DBPN 块从彩色图像中提取特征 $\{F_{de}^n\}_{n=1}^N$。最后将 $F_{de}^N$ 通过一个简单的卷积块映射到输出空间。得到深度估计网络的输出 $D_{de}$。
CT 是连接 DSRNet 和 DENet 的桥梁,实现了 DSRNet 和 DENet 之间的双边知识转移。CT 由两部分组成,即跨任务知识蒸馏(Cross-Task Distillation)和结构预测网络(Structure Prediction Network,SPNet),前者侧重于从两个网络中提取的多尺度特征之间的交互,而后者则使用结构图作为监督,进一步指导两个网络的学习。
3.2 跨任务知识蒸馏策略
知识蒸馏通常被认为是一种将有益的信息从一个性能最佳的模型转移到另一个简单模型的技术,其教师网络提前训练然后固定参数,而且假设它总是比学生网络能够学习更好的表示。不同于常用的蒸馏技术,本文的目标是协作训练 SRNet 和 DENet 并鼓励他们互相受益。
在相互学习(Mutual Learning)方法的启发下,本文提出了一种跨任务知识蒸馏方案,根据迭代的协作训练中老师和学生网络在深度恢复方面的当前表现,在两个任务之间进行师生角色切换。特别的,在当前这轮训练中,需要根据它们上一轮的表现提前确定老师。计算每个恢复深度图和对应真实深度图像之间的平均像素误差:
\begin{equation}\label{esr} e_{dsr} = \frac{1}{HW}\sum_h^H\sum_w^W|D_{sr}(h,w) -D_{hr}(h,w)|, \end{equation} \begin{equation}\label{ede} e_{de} = \frac{1}{HW}\sum_h^H\sum_w^W|D_{de}(h,w) -D_{hr}(h,w)|, \end{equation}式中 $\{H,W\}$ 为输出深度图像的大小。$e_{dsr}$ 小于 $e_{de}$ 时,DSRNet 的性能相对较好,成为引导 DENet 学习的老师网络,反之,$e_{de}$ 小于 $e_{dsr}$ 时,DENet 的性能相对较好,成为引导 DSRNet 学习的老师网络。
为了可以蒸馏出更有意义的、能够准确表达深度图像本质结构特征的知识,本文提出了一种多空间蒸馏策略,在输出空间和结构空间对知识进行迁移。
- (1) 输出空间蒸馏(Output Space Distillation) :为了确保深度图像中像素级深度值的局部信息传输,本章在 DSRNet 和 DENet 的中间加入了边界输出层(包含两个简单的卷积层)将两个网络的多级特征 $\left\{F_{s r}^{n}, F_{d e}^{n}\right\}_{n=1}^{N}$ 映射到输出空间。因此,输出空间蒸馏的损失函数被设计成间接对齐 DSRNet 和 DENet 之间的特征: \begin{equation} \mathcal{L}_{O}=\frac{1}{N} \sum_{n=1}^{N}\left\|D_{s r}^{n}-D_{d e}^{n}\right\|_{1} \end{equation}
- (2) 结构空间蒸馏(Affinity Space Distillation):彩色图像及其对应深度图像是对同一场景的不同表示,具有很强的结构相似性。在彩色图像中,外观相似的像素有更多的机会属于同一个对象,并且应该有接近的深度值。一些探索像素间相关性的工作考虑非局部相关来增强像素之间的相关特征,有利于深度图像恢复。本文也将非局部结构知识转移到结构空间,通过计算像素对之间的相似性来实现。 假设特征图 $F$ 的维度为 $h \times w \times c$,变形函数 $\mathbb{R}$ 的功能就是改变 $F$ 的维度为 $hw \times c$,相似度矩阵定义为: \begin{equation} A(F)=\sigma\left(\mathbb{R}(F) \otimes \mathbb{R}^{T}(F)\right) \end{equation} 其中,$\sigma(\cdot)$ 是 Softmax 激活函数,$\otimes$ 代表矩阵乘法,$T$ 是矩阵转置操作。所以结构空间蒸馏的损失函数定义为对齐 DSRNet 与 DENet 多级特征的相似度矩阵: \begin{equation} \mathcal{L}_{A}=\frac{1}{N} \sum_{n=1}^{N}\left\|A\left(F_{S r}^{n}\right)-A\left(F_{d e}^{n}\right)\right\|_{1} \end{equation} 整体的蒸馏损失函数为输出空间蒸馏损失与特征空间蒸馏损失的和: \begin{equation} \mathcal{L}_{\text {distill }}=\mathcal{L}_{O}+\gamma \mathcal{L}_{A} \end{equation} 其中,$\gamma$ 是一个平衡参数。$\mathcal{L}_{\text {distill }}$ 应该用于对学生网络的更新,而不是对老师网络的更新,这是由 $e_{dsr}$ 和 $e_{de}$ 之间的大小决定的。
3.3 结构预测子网络
结构预测网络(Structure Prediction Net,SPNet)的目标是根据 DSRNet 和 DENet 的特征图 $F_{sr}^N$ 和 $F_{de}^N$ 预测一个结构图 $S$,提供额外的结构正规化,帮助 DSRNet 和 DENet 学习更多的信息结构表示,缓解 RGB-D 结构不一致的问题。SPNet 通过由真实结构图 $S_{gt}$,$S_{gt}$ 通过计算真实高分辨率深度图像 $D_{hr}$ 中相邻像素的差值(梯度)得到。如图 3 所示,所示,SPNet 由一个融合模块和一个结构预测 CNN 组成,融合模块对 DSRNet 和 DENet 的特征图 $F_{sr}^N$ 和 $F_{de}^N$ 进行融合,结构 CNN 是一个轻量级网络,包含五个堆叠的卷积层,将融合后的特征映射到输出空间。通常 DSR 和 DE 任务的错误恢复通常发生在深度图像中的深度边界和精细结构附近的区域,具有较高的恢复不确定性。因此,本文不是简单地将 $F_{sr}^N$ 和 $F_{de}^N$ 连接起来送入到结构 CNN 中,而是设计一个不确定性诱导的注意力融合模块,通过将恢复的不确定性加入到特征图中来加强这些结构特征。因此,首先通过激活重建误差图来计算两个网络的不确定度 $U_{sr}$ 和 $U_{de}$:
\begin{equation} \begin{aligned} &U_{s r}=\sigma\left(\operatorname{Conv}_{1 \times 1}\left(D_{s r}-D_{h r}\right)\right. \\ &U_{d e}=\sigma\left(\operatorname{Conv}_{1 \times 1}\left(D_{d e}-D_{h r}\right)\right. \end{aligned} \end{equation}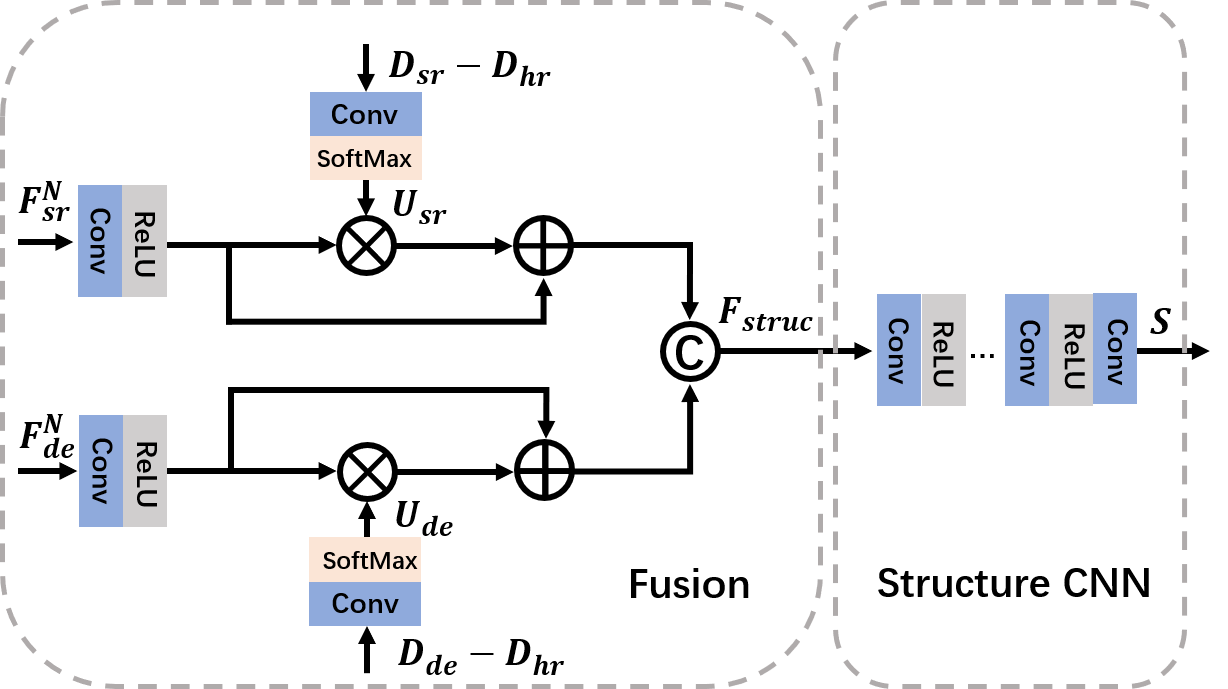
其中,$Conv_{1 \ times 1}$ 是一个卷积核大小为 $1 \times 1$ 的卷积层,作用是调整通道数。然后,使用不确定性映射重新对 $F_{sr}^N$ 和 $F_{de}^N$ 赋予权重并通过注意模块将其融合。
\begin{equation} F_{\text {struct }}=\left[F_{s r}^{N} *\left(1+U_{s r}\right), F_{d e}^{N} *\left(1+U_{d e}\right)\right] \end{equation}其中, $F_{\text {struct}}$ 是融合后的特征,$[\cdot]$ 表示串联操作,$*$ 表示像素级的乘法。通过从 SPNet在逆向信息流中反向传播的梯度,可以更新 DSRNet 和 DENet 的参数。
3.4 训练策略
整体的基于跨任务场景结构知识迁移的单张深度图像超分辨率网络的训练过程可以分为两个步骤,如算法 1 所示。
第一阶段:首先用真实深度图像 $D_{hr}$ 训练 DSRNet 和 DENet。损失的定义如下:
\begin{equation} \begin{gathered} \mathcal{L}_{D S R}=\left\|D_{s r}-D_{h r}\right\|_{1} \\ \mathcal{L}_{D E}=\lambda \frac{1-\operatorname{SSIM}\left(D_{d e}, D_{h r}\right)}{2}+(1-\lambda)\left\|D_{d e}-D_{h r}\right\|_{1} \end{gathered} \end{equation}其中,$L_{DSR}$ 是常见的像素级的 L1 损失函数用于监督 DSRNet 的学习,$L_{DE}$ 被定义为重建 L1 损失函数和结构相似度损失函数的和,$\lambda$ 是一个平衡参数。
第二阶段,在两个网络之间引入跨任务蒸馏损失函数 $\mathcal{L}_{\text {distill }}$,同时引入 SPNet,SPNet 和 DSRNet 与 DENet 同时训练。SPNet 的损失函数定义为:
\begin{equation} \mathcal{L}_{D S R}=\left\|\mathbb{G}\left(F_{\text {struc }}\right)-S_{g t}\right\|_{1} \end{equation}其中,$\mathbb{G}$ 表示 SPNet,$F_{\text {struct}}$ 为融合的特征。如果 DSRNet 被判定为学生,则 DENet 的参数在当前是固定的,DSRNet 将按照下面的损失函数进行更新:
\begin{equation} \mathcal{L}=\mathcal{L}_{D S R}+\rho_{1} \mathcal{L}_{\text {struc }}+\rho_{2} \mathcal{L}_{\text {distill }} \end{equation}其中,$\rho_1$ 和 $\rho_2$ 为平衡参数。当 DENet 被判定为学生,则 DSRNet 的参数在当前是固定的,DENet 将按照下面的损失函数进行更新:
\begin{equation} \mathcal{L}=\mathcal{L}_{D E}+\rho_{1} \mathcal{L}_{\text {struc }}+\rho_{2} \mathcal{L}_{\text {distill }} \end{equation}
% This quicksort algorithm is extracted from Chapter 7, Introduction to Algorithms (3rd edition)
\begin{algorithm}
\caption{Quicksort}
\begin{algorithmic}
\Require Training data {$D_{lr}$, $D_{hr}$, $I$, $S_{gt}$} %three networks $W_{SR}$, $W_{DE}$ and $W_{GE}$ \\Initialise $W_{SR}$, $W_{DE}$ and $W_{GE}$
\STATE ---------------- Step 1 ----------------
\State Randomly initialize DSRNet and DENet
\FOR {i = 1; i $\le$ 100}
\STATE Train DSRNet and DENet with $\mathcal{L}_{DSR}$ and $\mathcal{L}_{DE}$, respectively
\EndFOR
\STATE ---------------- Step 2 ----------------
\STATE Randomly initialize SPNet
\FOR {i = 101; i $\le$ max epoch}
\STATE Compute the average error value $e_{dsr}$ and $e_{de}$ according to Eq.(1) and Eq.(2)
\IF {$e_{dsr} \le e_{de}$}
\STATE Fix DSRNet and update DENet with
\STATE $\mathcal{L} = \mathcal{L}_{DE} + \rho_1\mathcal{L}_{struc} + \rho_2\mathcal{L}_{distill}$
\ELSE
\STATE Fix DENet and update DSRNet with
\STATE $\mathcal{L} = \mathcal{L}_{DSR} + \rho_1\mathcal{L}_{struc} + \rho_2\mathcal{L}_{distill}$
\EndIF
\EndFOR
\Ensure $D_{sr}$
\end{algorithmic}
\end{algorithm}
3. Experiments
以 MIDDLEBURY 数据集为例,首先在四个常见倍率($2\times$、$4\times$、$8\times$ 和 $16\times$)的超分辨率任务上对比了多个最先进的深度图像超分辨率方法,如表 1 所示。得益于 DBPN 骨干网络,DSRNet w/o CT 的性能超过了以前的大多数方法,但略低于最近的先进的方法。
|
|
|
Art |
|
|
Books |
|
|
Dolls |
|
|
Laundry |
|
|
Mobius |
|
|
Reindeer |
|
|
×4 |
×8 |
×16 |
×4 |
×8 |
×16 |
×4 |
×8 |
×16 |
×4 |
×8 |
×16 |
×4 |
×8 |
×16 |
×4 |
×8 |
×16 |
|
|
CLMF |
0.76/8.12 |
1.44/17.28 |
2.87/33.25 |
0.28/3.27 |
0.51/7.25 |
1.02/16.09 |
0.34/4.40 |
0.60/8.76 |
1.01/18.32 |
0.50/5.50 |
0.80/12.67 |
1.67/25.40 |
0.29/4.13 |
0.51/8.42 |
0.97/17.27 |
0.51/4.65 |
0.84/9.96 |
1.55/18.34 |
|
JGF |
0.47/3.25 |
0.78/7.39 |
1.54/14.31 |
0.24/2.14 |
0.43/5.41 |
0.81/12.05 |
0.33/3.23 |
0.59/7.29 |
1.06/15.87 |
0.36/2.60 |
0.64/4.54 |
1.20/8.69 |
0.25/3.36 |
0.46/6.45 |
0.80/12.33 |
0.38/2.27 |
0.64/5.17 |
1.09/11.84 |
|
EDGE |
0.65/6.82 |
1.03/13.49 |
2.11/25.90 |
0.30/3.35 |
0.56/8.50 |
1.03/19.32 |
0.31/2.90 |
0.56/6.84 |
1.05/17.97 |
0.32/2.82 |
0.54/5.46 |
1.14/13.57 |
0.29/3.72 |
0.51/7.36 |
1.10/14.05 |
0.37/2.67 |
0.63/6.22 |
1.28/16.80 |
|
TGV |
0.65/5.14 |
1.17/10.51 |
2.30/21.37 |
0.27/2.48 |
0.42/4.65 |
0.82/11.20 |
0.33/4.45 |
0.70/11.12 |
2.20/45.54 |
0.55/6.99 |
1.22/16.32 |
3.37/53.61 |
0.29/3.68 |
0.49/6.84 |
0.90/14.09 |
0.49/4.67 |
1.03/11.22 |
3.05/43.48 |
|
KSVD |
0.64/3.46 |
0.81/5.18 |
1.47/8.39 |
0.23/2.13 |
0.52/3.97 |
0.76/8.76 |
0.34/4.53 |
0.56/6.18 |
0.82/12.98 |
0.35/2.19 |
0.52/3.89 |
1.08/8.79 |
0.28/2.08 |
0.48/4.86 |
0.81/8.97 |
0.47/2.19 |
0.57/5.76 |
0.99/12.67 |
|
CDLLC |
0.53/2.86 |
0.76/4.59 |
1.41/7.53 |
0.19/1.34 |
0.46/3.67 |
0.75/8.12 |
0.31/4.61 |
0.53/5.94 |
0.79/12.64 |
0.30/2.08 |
0.48/3.77 |
0.96/8.25 |
0.27/1.98 |
0.46/4.59 |
0.79/7.89 |
0.43/2.09 |
0.55/5.39 |
0.98/11.49 |
|
PB |
0.79/3.12 |
0.93/6.18 |
1.98/12.34 |
0.16/1.39 |
0.43/3.34 |
0.79/8.12 |
0.53/3.99 |
0.83/6.22 |
0.99/12.86 |
1.13/2.68 |
1.89/5.62 |
2.87/11.76 |
0.17/1.95 |
0.47/4.12 |
0.82/8.32 |
0.56/6.04 |
0.97/12.17 |
1.89/21.35 |
|
EG |
0.48/2.48 |
0.71/3.31 |
1.35/5.88 |
0.15/1.23 |
0.36/3.09 |
0.70/7.58 |
0.27/2.72 |
0.49/5.59 |
0.74/12.06 |
0.28/1.62 |
0.45/2.86 |
0.92/7.87 |
0.23/1.88 |
0.42/4.29 |
0.75/7.63 |
0.36/1.97 |
0.51/4.31 |
0.95/9.27 |
|
SRCNN |
0.63/7.61 |
1.21/14.54 |
2.34/23.65 |
0.25/2.88 |
0.52/7.98 |
0.97/15.24 |
0.29/3.93 |
0.58/8.34 |
1.03/16.13 |
0.40/6.25 |
0.87/13.63 |
1.74/24.84 |
0.25/3.63 |
0.43/7.28 |
0.87/14.53 |
0.35/3.84 |
0.75/7.98 |
1.47/14.78 |
|
DSP |
0.73/7.83 |
1.56/15.21 |
3.03/31.32 |
0.28/3.19 |
0.61/8.52 |
1.31/16.73 |
0.32/4.74 |
0.65/9.53 |
1.45/19.37 |
0.45/6.19 |
0.98/12.86 |
2.01/22.96 |
0.31/3.89 |
0.59/8.23 |
1.26/16.58 |
0.42/3.59 |
0.84/7.23 |
1.73/14.12 |
|
ATGVNet |
0.65/3.78 |
0.81/3.78 |
1.42/9.68 |
0.43/5.48 |
0.51/7.16 |
0.79/10.32 |
0.41/4.55 |
0.52/6.27 |
0.56/12.64 |
0.37/2.07 |
0.89/3.78 |
0.94/8.69 |
0.38/3.47 |
0.45/4.81 |
0.80/8.56 |
0.41/3.82 |
0.58/5.68 |
1.01/12.63 |
|
MSG |
0.46/2.31 |
0.76/4.31 |
1.53/8.78 |
0.15/1.21 |
0.41/3.24 |
0.76/7.85 |
0.25/2.39 |
0.51/4.86 |
0.87/9.94 |
0.30/1.68 |
0.46/2.78 |
1.12/7.62 |
0.21/1.79 |
0.43/4.05 |
0.76/7.48 |
0.31/1.73 |
0.52/2.93 |
0.99/7.63 |
|
DGDIE |
0.48/2.34 |
1.20/13.18 |
2.44/26.32 |
0.30/3.21 |
0.58/7.33 |
1.02/14.25 |
0.34/4.79 |
0.63/9.44 |
0.93/11.66 |
0.35/2.03 |
0.86/3.69 |
1.56/16.72 |
0.28/1.98 |
0.58/8.11 |
0.98/16.22 |
0.35/1.76 |
0.73/7.82 |
1.29/15.83 |
|
DEIN |
0.40/2.17 |
0.64/3.62 |
1.34/6.69 |
0.22/1.68 |
0.37/3.20 |
0.78/8.05 |
0.22/1.73 |
0.38/3.38 |
0.73/9.95 |
0.23/1.70 |
0.36/3.27 |
0.81/7.71 |
0.20/1.89 |
0.35/3.02 |
0.73/7.42 |
0.26/1.40 |
0.40/2.76 |
0.80/5.88 |
|
CCFN |
0.43/2.23 |
0.72/3.59 |
1.50/7.28 |
0.17/1.19 |
0.36/3.07 |
0.69/7.32 |
0.25/1.98 |
0.46/4.49 |
0.75/9.84 |
0.24/1.39 |
0.41/2.49 |
0.71/7.35 |
0.23/2.18 |
0.39/3.91 |
0.73/7.41 |
0.29/1.51 |
0.46/2.79 |
0.95/6.58 |
|
GSRPT |
0.48/2.53 |
0.74/4.18 |
1.48/7.83 |
0.21/1.77 |
0.38/4.23 |
0.38/4.23 |
0.28/2.84 |
0.48/4.61 |
0.79/10.12 |
0.33/1.79 |
0.56/4.55 |
1.24/8.98 |
0.24/2.02 |
0.49/4.70 |
0.80/8.38 |
0.31/1.58 |
0.61/5.90 |
1.07/10.35 |
|
Ours. |
0.26/1.95 |
0.51/3.45 |
1.22/6.28 |
0.15/1.13 |
0.26/2.87 |
0.59/6.79 |
0.19/1.35 |
0.32/3.22 |
0.59/8.92 |
0.17/1.27 |
0.34/2.41 |
0.71/6.88 |
0.16/1.21 |
0.26/2.87 |
0.67/6.73 |
0.17/1.28 |
0.34/2.40 |
0.74/5.66 |

当与 DENet 一起进行跨任务交互的的协同训练时,本文的 DSRNet 的性能比不带 CT 时的 DSRNet 更进一步,与 DSRN 性能相当,甚至在至少一半的测试样本中比 DSRN 性能更好。需要强调的是,与这些色彩指导的 DSR 方法不同,在测试阶段仅使用单张 LR 深度图像作为网络输入,没有 HR 彩色图像的帮助,但在准确性和运行时间都取得了令人满意的结果。如图 \ref{fig:compar} 所示,展示了 $8 \times$ DSR 的主观结果。对于结构细节,如第一个测试样本中的棍子和茶壶柄,第二张测试样本中的玩具轮廓,本文的基于场景结构的跨任务迁移框架,在不引入纹理模糊的情况下,清晰地恢复了这些区域。
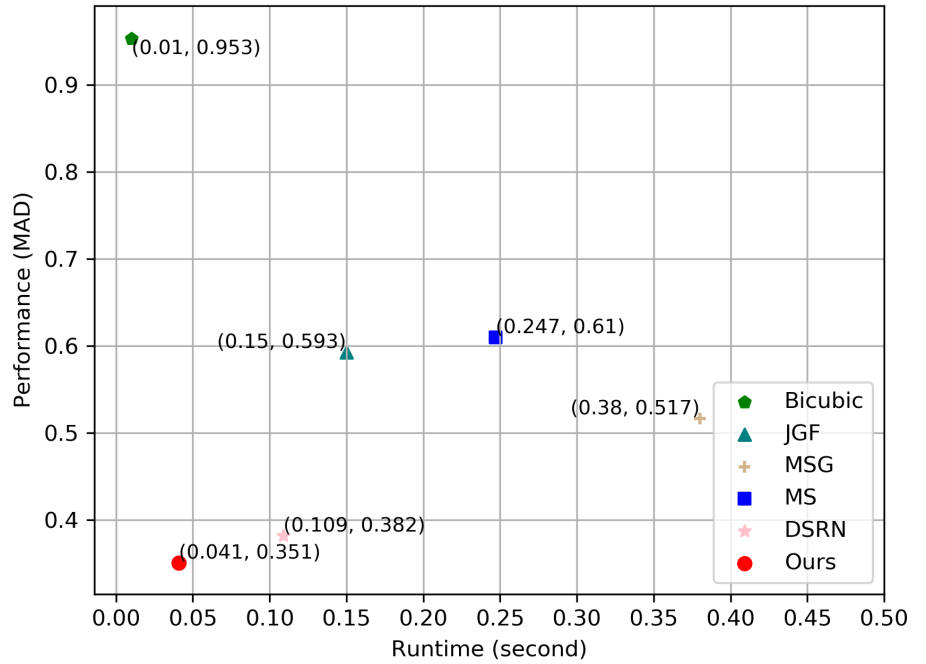
在图 5 中,通过精确度和运行时之间的权衡总结了总体性能。在Middlebury 数据集上,在完全分辨率约 $1080 \times 1320$ 的测试样例上测试了 $8 \times$ DSR 的运行时间和准确度。由于在测试阶段使用了 HR 彩色图像,彩色指导方法即 JGF,MSG 和 DSRN 比本章的方法运行得慢。MS 是 MSG 的单张深度图 DSR 版本,但在准确性和速度上仍然不如本章的方法。由于任务间的交互作用,本章的方法以最小的推理时间获得了满意的恢复结果。